The System
I will now describe the architecture of the dialog markets system. I will first talk about sequential and tree-structured dialogs, the different roles they play, and how they can be integrated. Shortly after, I will discuss how to incentivize high-quality contributions to dialogs. To facilitate this, I first need to talk about what I mean by a “contribution”. I will then introduce the reward distribution problem, but mostly postpone its discussion to the next section. Finally, I will describe a set of components, including user interfaces, that together could form a practical dialog market.
Table of contents
Dialogs
A dialog is initiated by a person (or a program) who I will call the author (or asker). A dialog starts when the author asks a question. The goal of the dialog is to solve the problem that prompted the author to start the dialog.
Sequential conversations
When I hear “dialog”, my first association is with one-on-one conversations that proceed in a sequential manner, with each of the conversation partners taking turns. In the context of this project, I’m particularly thinking about text-based dialogs where each contribution is a short chat message, and where each participant can “append” a new response to the conversation at any time. This is a natural mode of interaction for most people. If someone asks a question, then this mode is well-suited for asking follow-up questions, receiving clarification, and providing small amounts of information. At each point in time, there is a clear context for new responses. If a question is asked, it is generally up to the other participant to either answer it or reject it by changing the topic.
Tree-structured conversations
While sequential dialogs are well-suited for transmitting information between two people, they are less well-suited for communication within a group, and also less well-suited as a means of knowledge representation. Within a group, we would like to keep track of multiple discussions at once. In this setting, hierarchical structure helps: it lets us navigate to the desired sub-discussion more quickly and allows different people to discuss different topics simultaneously. Tree-structured comment threads in particular have proven useful for discussions on the web. In this project, we’re particularly interested in tree-structured discussions where each comment is either a follow-up question or a response to a question. We can generalize the traditional setup slightly by allowing graph-structured discussions, i.e. the same sub-conversation can be included in multiple places within and across dialogs.
Integrating sequential and tree-structured conversations
In our case, we need to structure the interaction between the asker and a group of answerers. We’ll consider sequential dialogs for the interaction between the group of answerers (treated as a single entity) and the asker, and tree-structured dialogs for the interactions within the group of askers and as a means of knowledge representation.
How do we integrate sequential and tree-structured dialogs? As a first
step towards integration, imagine that we allow contributions in the
tree-structured dialog to be sent to the asker’s sequential dialog. This
could happen by marking such contributions with @asker or @author.
However, this may lead to chaos, since multiple questions may be posed
nearly simultaneously, and since questions won’t always fit into the
flow of the sequential conversation. One way to address this is to
not send contributions @asker directly to the
sequential conversation, but rather to a list of candidate responses.
This allows the system to decide more systematically which of these
candidates to send next, based on various signals (e.g. upvotes that are
reset whenever a new response is posted to the sequential conversation).
Since the tree-structured dialog also serves as the repository of knowledge about the current state of problem-solving for the asker’s question, it’s not enough to allow users to add to it. We also want users to be able to make edits, deletions, and structure changes, analogous to how you might edit a Wikipedia page. This changes the dynamics somewhat: when users add to the tree-structured dialog, they don’t “own” what they add; others can change it when they see room for improvement.
Contributions
Questions and answers
Let’s talk briefly about what individual elements in the tree-structured dialog may look like. There is a single top-level question. All other elements are either follow-up questions (to the top-level question, or to another follow-up question), or responses to questions. A response is not necessarily a complete answer. For example, if the question is “What are some potential causes of the flu?”, a single response could be “Influenza virus type A”.
Questions can restrict their answer format. This is most useful for questions directed at the asker, since we would like to minimize how much work they need to do. For example, there can be binary, multiple-choice, fill-in-the-blank, and free-form questions. We can also imagine more complex answer formats, such as files that need to be uploaded, camera pictures that need to be taken, or locations on a map that need to be selected.
Arbitrary dialog actions
In the next section, I’ll talk about how we want to reward contributions based on how helpful they are. This will require that we know what we mean by a “contribution”. As mentioned above, in addition to adding content to a dialog, there are other actions that users can take to modify the state of the dialog: They can make edits and structure changes, delete content, propose to send a notification to the asker, perhaps upvote such a proposal, perhaps propose to pay a reward to some user, and there are probably other actions that I am not thinking of right now. So, when I am talking about a “contribution” in the following, I will refer to the set that includes all such actions that change the state of the dialog in one way or another. This is comparable to making changes to a set of files and directories under git version control: each commit is an action.
Incentives
Associating rewards with dialogs
When the asker starts a dialog by posing a question, they can also pledge a reward. (I will primarily be thinking about monetary rewards, but we could also replace this with another quantifiable, transferable source of value, such as magic Internet points.) The role of the dialog market system is to distribute this reward to (the authors of) contributions based on how helpful they are, in order to incentivize dialogs that are most helpful to the asker (discussed in the next section). Pledges draw the attention of answerers to dialogs with the highest rwards. The asker (and other users) may also be able to pledge additional rewards for sub-questions in the tree-structured dialog in order to encourage additional work on these questions.
What are rewards used for?
How can we distribute rewards in a way that incentivizes dialogs to be as helpful as possible? There are at least two ways in which the system can use rewards:
-
Rewards can be distributed directly to users who supply good contributions of any kind (useful follow-up questions, helpful edits, informative votes, etc.).
-
Rewards can pay for the work necessary to determine which contributions are good. This can happen through auxiliary questions that are asked within the system (“How good is the following question/answer within its context?”). Note the recursion—we can ask the meta-question about answers to this question as well, but the available resources diminish quickly.
Desiderata for reward distribution
I’ll discuss reward distribution strategies in more depth in Section V. For now I want to cover some general properties that we would want this use of resources to have, ideally:
-
Byzantine fault-tolerance: Even if some participants (people or programs) act maliciously—e.g. by providing unhelpful questions, or intentionally incorrect answers—we would like the overall system to perform its function undisturbed. This includes a number of special cases:
-
Spam resistance: As a special case of fault-tolerance, we would like the system to be resistant to spamming of unhelpful responses. One way to accomplish this is by making all contributions costly, under the assumption that participants will pay because they expect their contributions to pay dividends over time. If every participant pays a small fee for their contributions, then low-quality contributions (if present) could subsidize high-quality ones.
-
Manipulation resistance: Suppose I ask the question “Should I go to conference z?”, and suppose that, under reflection, the arguments for and against are roughly equal in strength. The organizers of the conference have incentive to supply arguments in favor. If such arguments are provided in response to a subquestion “What are arguments in favor?”, then no conflict of interest is present. On the other hand, if the organizers then provide an affirmative answer to the overall question, pointing to the arguments in favor, the judgment is biased. We would like to set up incentives such that the overall mechanism is incentive-compatible, i.e., such that every participant is best off reporting their true beliefs.
-
Stability in the presence of high rewards: We would like the system to scale to scenarios where some questions have very high rewards, so it is important that the mechanism cannot be gamed.
-
-
Allocate money and time in a way that reflects what people care about: If a subquestion is part of many dialogs, we want a lot of money to flow to this question in order to direct participants’ attention towards its solution.
-
Sane temporal dynamics: Contributions that turn out to be good later, but don’t look good now, should still be rewarded eventually. This could be accomplished by distributing money over a longer period of time. It is impossible to have most of the payoff in the future at all points in time, but we could use some (temporally) heavy-tailed way of distributing money, although that raises concerns related to human psychology and discounting. The economically sound way to do this would be something like a prediction market on future judgments, but this would likely introduce a lot of overhead.
Architecture
Let’s talk about a system that could make use of the principles described so far.
A minimal core
A key design goal behind this system is that its core is minimal. To the extent that complex mechanisms are necessary to answer questions, we would like to offload this work as much as possible to market participants, such that these mechanisms can be subject to improvement under competitive pressures over time.
For example, one can imagine sophisticated knowledge representation mechanisms for automating parts of dialogs. We would not want such structures to be part of the core system.
Similarly, there are many specific techniques we could use to improve the quality of contributions in this kind of system (e.g., Eigentrust, Bayesian optimization, Bayesian truth serum, ask about counterfactuals, adversarial setups, costly identities + reputation). My hope is that we can find a core market mechanism that establishes the right incentives, so that adding other techniques (via bots, see below) is profitable if and only if it improves the quality of dialogs.
I will now talk about the different (central and less central) components of the system: there is the dialog market itself, the reward computation system, user interfaces, and automation through bots.
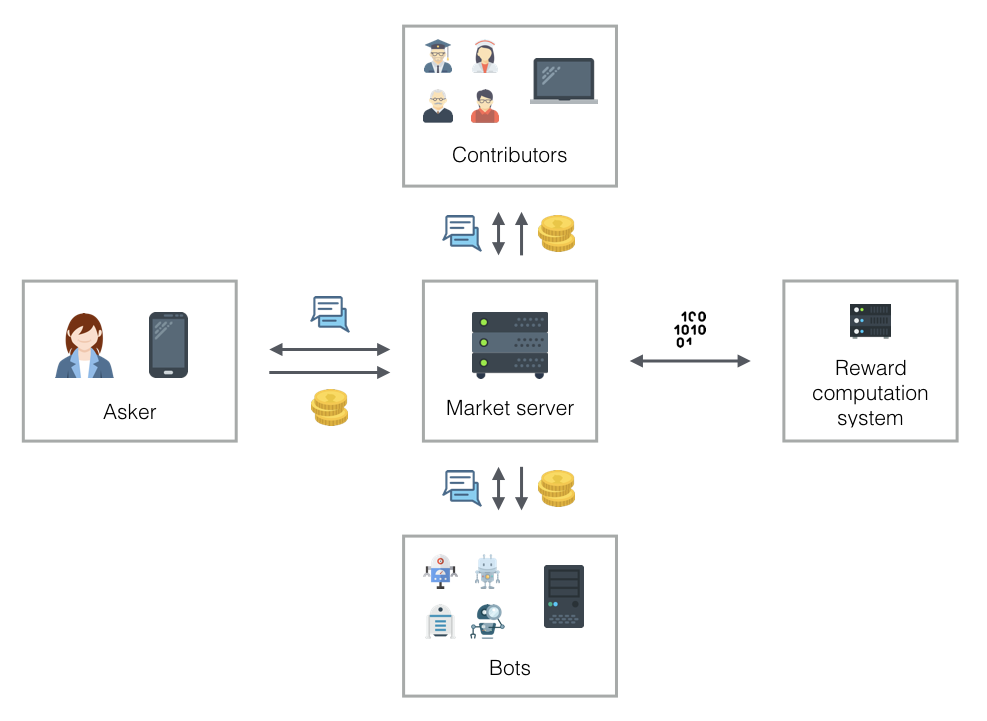
Dialog market server
The dialog market server manages user accounts, the creation of dialogs and contributions, and incoming and outgoing payments. The distribution of payments depends on the reward computation system. The dialog market server is simply an API endpoint, i.e., it only talks to other machines; there is no user interface. This is the primary point of interaction for people who write bots.
Reward computation system
The reward computation system takes as input a pointer to a dialog and (control of) a budget for judging the contributions in this dialog. It returns (eventually) an answer to the question of how to divide up the total reward over individual contributions. This system is also just an API endpoint and doesn’t interact with users directly. It depends on the dialog market, as it may need to create dialogs and sub-questions to elicit information that is needed to compute rewards.
User interfaces
I can think of two user interfaces that would be useful.
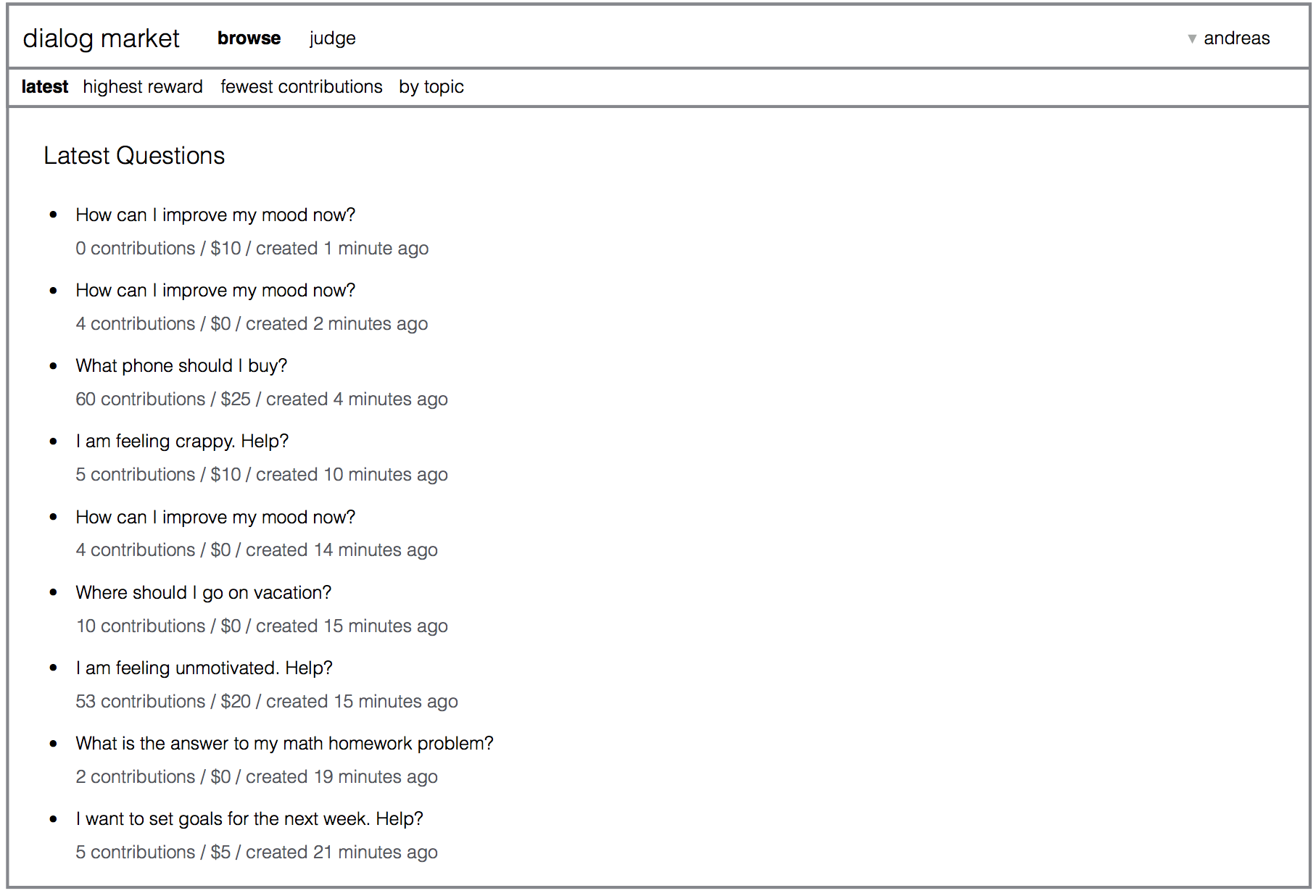
First, a website could provide a user-accessible view of the dialog market. It could provide a way to browse and search dialogs, and to contribute to dialogs. This could be the primary point of contact for people who answer questions, make edits, ask follow-up questions, etc. For example, the website could look as shown below.
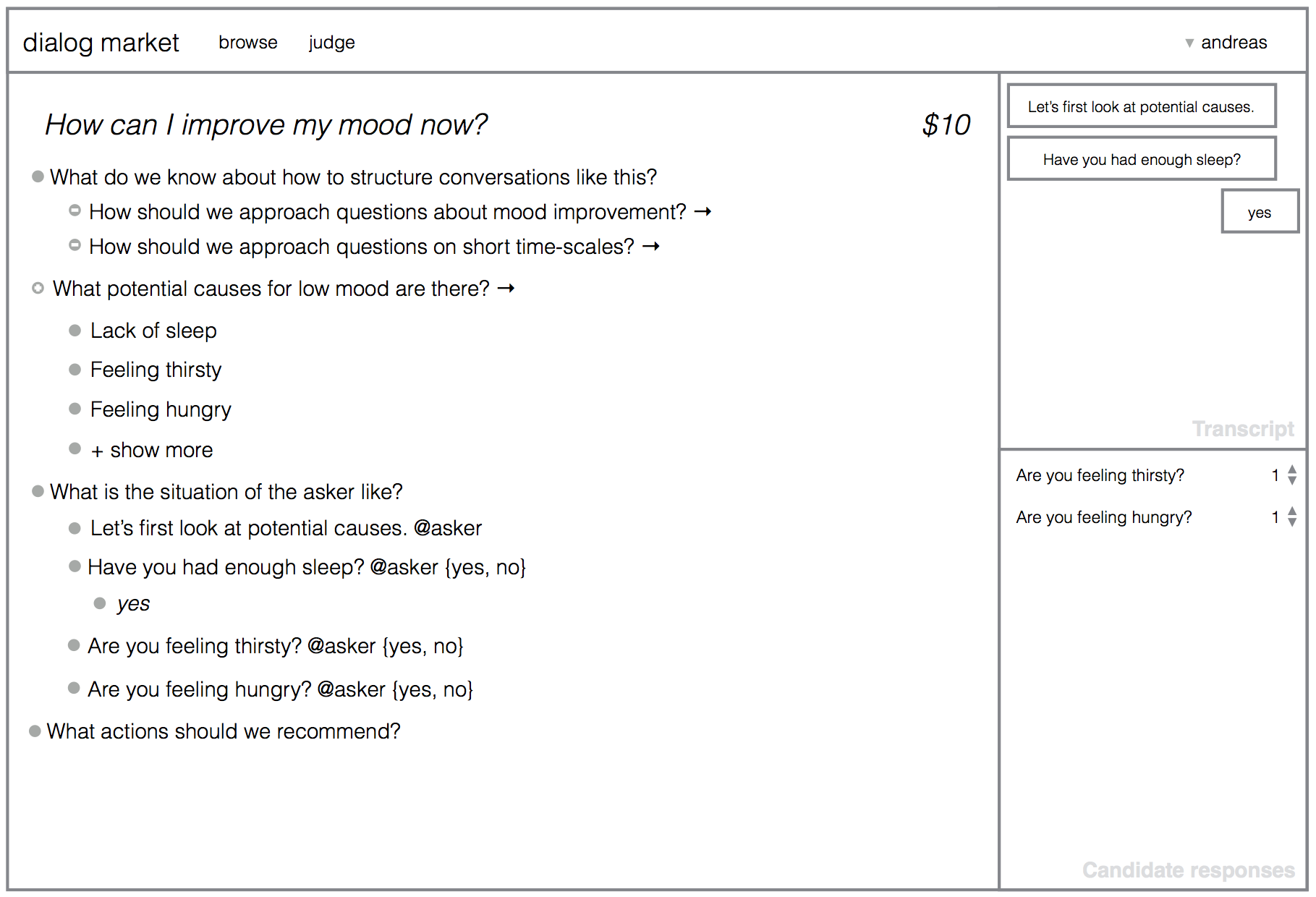
Second, a smartphone app could be the primary point of interaction for users who seek to have their questions answered. The app could be used to quickly submit questions, to browse answers and follow-up questions, and to answer follow-up questions directed at the dialog author. The follow-up questions would be encouraged to be easy to answer on a smartphone, e.g. by making them multiple-choice. The app could then show regular updates on a user’s questions, requiring only small, easy inputs now and then to keep progress going. Users could get push notifications when new answers or follow-up questions are available. The app could look similar to the one shown here:


Automation using bots
Finally, there are programs that interact with the dialog market server. I’ll call these programs bots. This component is not strictly necessary, and may to a large extent be developed by people outside of the organization running the market, but I expect that it will play a key role.
Initially, I expect almost all answers to come from humans. Over time, some answers and follow-up questions will repeat. A simple bot could replay contributions that were previously useful in the same context. The notion of context identity used here could be expanded over time using natural language processing tools. In this way, the system supports incremental automation.
Over time, this could result in good decision trees: bots could automate more and more contributions until the entire process of solving common problems is automated except for border cases. In other words, after some time, no human intervention would be necessary to solve the most common problems; only when we get to the fringes of the decision tree would human intervention be necessary.
Other possible bots include a Mechanical Turk bot (that simply outsources questions to Amazon’s Mechanical Turk), and simple pattern matching bots (e.g., for Boolean questions such as “Is it the case that x?”, it could ask the subquestions “What are arguments that x?” and “What are arguments that not x?”).